
Description
The procedure includes ten different gestures whose details are reported in Table 1, together with an abbreviation of the gesture itself. The dataset we propose was collected with the support of professors from the Department of Medicine, Surgery and Dentistry – “Schola Medica Salernitana” of the University of Salerno, Italy.
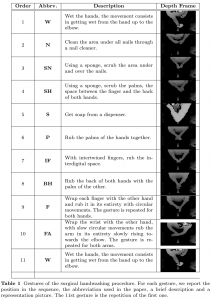
The procedure was simulated by 53 different voluntaries, equally distributed between males (27) and females (26). The participants also had different height, so implying that the procedure was performed at different distances with respect to the camera. All the participants signed an informed consent. Each voluntary was properly trained by a medical doctor before performing the procedure; furthermore, during the procedure itself, a video with the specific gesture to be performed was shown to the worker. Also, each sequence was validated by a doctor before its insertion into the dataset.
The camera used for the acquisition of the dataset is an Intel® RealSense™ Depth Camera D435. The camera is controlled by a NVIDIA® Jetson Nano™ computing platform equipped with Quad-core ARM® Cortex™A57 CPU, a NVIDIA Maxwell™ with 128 core NVIDIA CUDA® GPU and 4GB LPDDR4 64-bit of RAM running Ubuntu operating system.
The camera is mounted at a height above the washbasin of Dplane = 0.9m, in a zenithal position; the top view allows for the movements of the hands and of the arms without any occlusions; furthermore, the chosen height also entirely captures the area where the worker has to move for washing his/her hands.
The dataset consists of 74 depth video sequences; each video contains the sequence of the ten gestures, obtained by a continuous capture of the whole hand washing procedure performed by a worker. The depth images are represented in 16 bits, where each pixel represents the distance from the camera (in millimeters). Each image is captured at a resolution of 640 × 480, and the acquisition is performed at 15 frames per second.
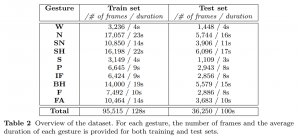
The dataset was partitioned into training and test set. The training set is composed of 50 sequences recorded by 41 different subjects; the test set includes the remaining 24 sequences, performed by 12 different subjects. In the whole, the dataset consists of more than 131, 000 frames, as reported in Table 2. The table also reports for each gesture the number of frames and the average duration. We can note that the average duration of the gestures ranges from short gestures (4 seconds), such as W and S, to long gestures (more than 20 seconds), such as N and SH.
[1] WHO, “Chapter 13, surgical hand preparation: state-of-the-art,” in WHO Guidelines on Hand Hygiene in Health Care: First Global Patient Safety Challenge Clean Care Is Safer Care, W. H. Organization, Ed. Genevra: WHO, 2009, ch. 13, pp. 54–60. [Online]. Available: https://www.ncbi.nlm.nih.gov/books/NBK144036/
