Contest

Pedestrian attributes recognition from images is nowadays a relevant problem in several real applications, such as digital signage, social robotics, business intelligence, people tracking and multi-camera person re-identification. To this concern, there is a great interest for recognizing simultaneously several information regarding pedestrians. It is worth pointing out that using a single classifier for recognizing each pedestrian attribute may require prohibitive computational resources (not always available) for obtaining them in real-time; in this scenario, nowadays multi-task learning approaches represent an excellent solution for maintaining the processing time unchanged as the number of pedestrian attributes increases.
The Pedestrian Attribute Recognition (PAR) Contest is a competition among methods for pedestrian attributes recognition from images. For the contest, we propose the use of a novel training set, the MIVIA PAR Dataset, partially annotated with five pedestrian attributes, namely color of the clothes (top and bottom), gender (female, male), bag (y/n), hat (y/n), and we restrict the competition to methods based on multi-task learning. The participants are encouraged to use additional samples or to produce themselves the missing annotations; this possibility is allowed in the competition only under the constraint that the additional samples and annotations are made publicly available, to give a relevant contribution to the diffusion of public datasets for pedestrian attributes recognition. After the contest, the dataset, also augmented with additional samples and annotations produced by the participants, will be made publicly available for the scientific community and will hopefully become among the biggest dataset of pedestrian attributes with this set of annotations. The performance of the competing methods will be evaluated in terms of accuracy on a private test set composed by images that are different from the ones available in the training set.
Dataset
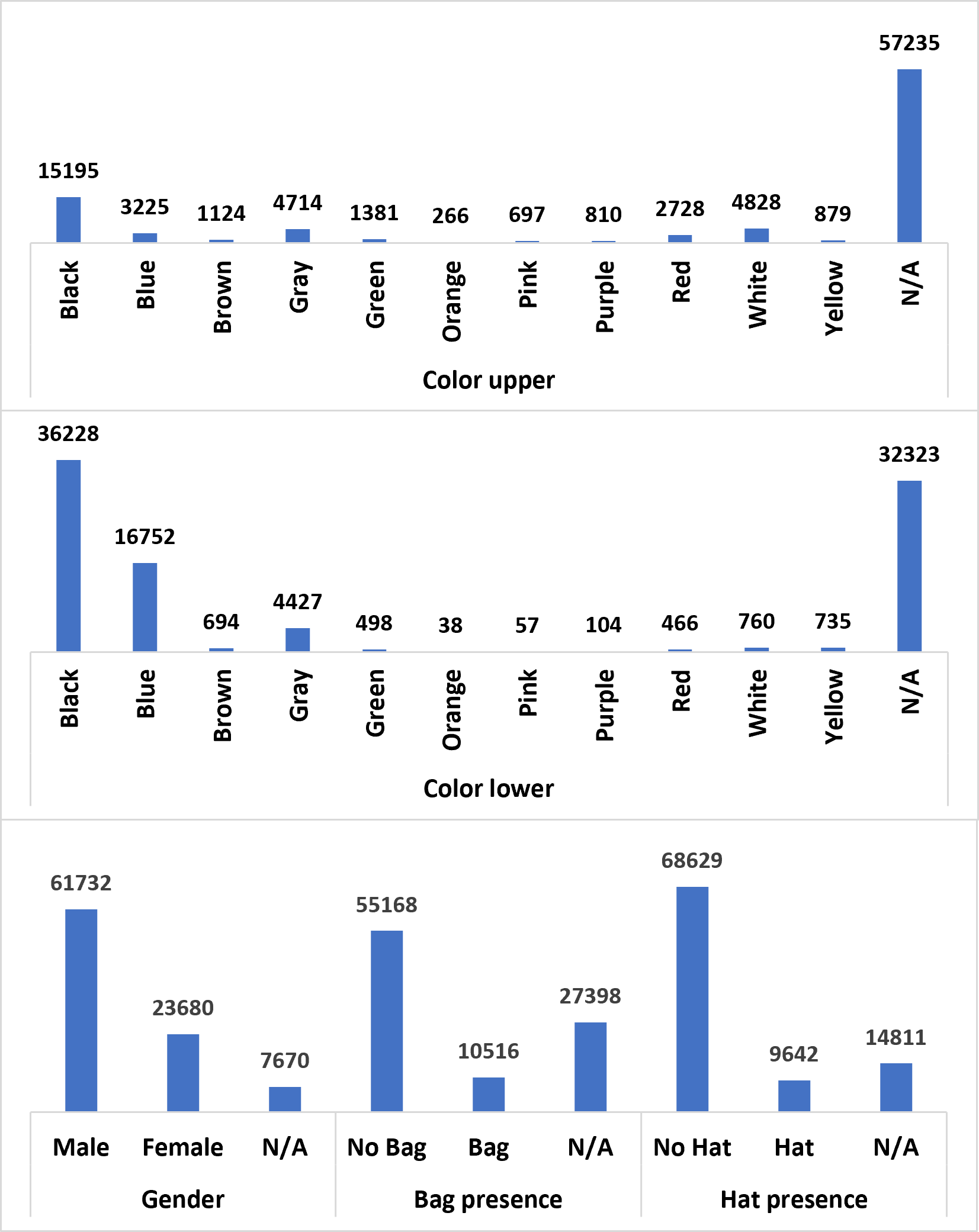
The MIVIA PAR Dataset consists of 105,244 images (93,082 in the training set and 12,162 in the validation set) annotated with the following labels (or part of them):
- Color of the clothes (upper and lower): the considered values are black, blue, brown, gray, green, orange, pink, purple, red, white, and yellow and are represented, in this order, with the labels [1,2,3,4,5,6,7,8,9,10,11].
- Gender: the considered values are male and female, represented in this order with the values [0,1].
- Bag: we consider the absence or presence of a bag, representing it with the values [0,1].
- Hat: we consider the absence or presence of a hat, representing it with the values [0,1].
The distribution of the samples in the training set is depicted on the left (N/A indicates the unavailability of the annotation); it is evident that the dataset is unbalanced, so the participants should deal with this imbalance. The samples have been collected from existing datasets (e.g. PETA, RAP, Colorful), by manually annotating the missing attributes, and obtained from private images, by extracting the image crop of the person and manually annotating the considered pedestrian attributes. Since the images are collected in different conditions, the dataset is heterogeneous in terms of size, illumination, pose of the person, distance from the camera. Each image of the dataset contains a single person, already cropped. We make available to the participants two folders with the training and validation images and a CSV file for each set with the labels of the samples.
Since the goal of this contest is the development of the research on pedestrian attributes recognition, we encourage participants to use other samples or to add missing labels for training their models, if such additional samples and annotations are made publicly available. The diffusion of samples annotated with pedestrian attributes would make a great contribution to the development of this line of research and to the realization of real applications in this field.
Evaluation protocol
The methods proposed by the participants will be evaluated in terms of mean accuracy on a private test set.
If $K$ is the number of samples in the test set and denoted $p_i$ the prediction of a method for the i-th sample of the test set and $g_i$ its groundtruth label, the accuracy $A$ is defined as the ratio between the number of correct classifications and the total number of samples:
$ A= \frac{\sum_{i=1}^K (p_i==g_i)}{K} $
We compute the accuracy for the five pedestrian attributes:
- $A_u$: accuracy in the recognition of the color of the clothes in the upper part of the body
- $A_l$: accuracy in the recognition of the color of the clothes in the lower part of the body
- $A_g$: gender recognition accuracy
- $A_b$: bag presence recognition accuracy
- $A_h$: hat presence recognition accuracy
We define the ranking of the contest according to the mean accuracy (mA), namely the mean of the abovementioned accuracies:
$ mA= \frac{A_u+A_l+A_g+A_b+A_h}{5} $
The method which achieves the highest $mA$ will be the winner of the Pedestrian Attribute Recognition Contest since it will demonstrate the highest average accuracy in the various tasks.
Rules
- The deadline for the submission of the methods is 30th June, 2023. The submission must be done with an email in which the participants share (directly or with external links) the trained model, the code and the report. Please follow the detailed instructions reported here.
- The participants can receive the training set, the validation set and their annotations by sending an email, in which they also communicate the name of the team.
- The participants can use these training and validation samples and annotations, but they can also use additional samples and/or add the missing labels, under the constraint that they make the additional samples and annotations publicly available.
- The participants must provide, for each sample, the prediction for all the considered pedestrian attributes, by training their multi-task neural network. For this reason, the validation set contains only fully annotated pedestrian samples. The teams are free to design novel neural network architectures or to define novel training procedures and loss functions for multi-task learning. Particularly welcome are the methods dealing with the missing labels.
- The participants must submit their trained model and their code by carefully following the detailed instructions reported here.
- The participants are strongly encouraged to submit a contest paper to CAIP 2023, whose deadline is 10th July, 2023. The contest paper must be also sent by email to the organizers. Otherwise, the participants must produce a brief PDF report of the proposed method, by following a template
that can be downloaded here. If you submit a paper, you can cite the paper describing the contest by downloading the bibtex file or as follows:
- Greco A., Vento B., "PAR Contest 2023: Pedestrian Attributes Recognition with Multi-Task Learning", 20th International Conference Computer Analysis of Images and Patterns, CAIP 2023
Instructions
The methods proposed by the participants will be executed on a private test set. To leave the participants totally free to use all the software libraries they prefer and to correctly reproduce their processing pipeline, the evaluation will be done on Google Colab (follow this tutorial) by running the code submitted by the participants on the samples of our private test set.
Therefore, the participants must submit an archive (download an example) including the following elements:
-
A Python script
test.py, which takes as inputs a CSV file with the same format of the training annotations (--data) and the folder of the test images (--images) and produces as output a CSV file with the predicted attributes for each image (--results). Thus, the script may be executed with the following command:
python test.py --data foo_test.csv --images foo_test/ --results foo_results.csv -
A Google Colab Notebook
test.ipynb, which includes the commands for installing all the software requirements and executes the scripttest.py. - All the files necessary for running the test, namely the trained model, additional scripts and so on.
The provided sample test.py also includes the reading of the CSV file with the annotations. Each raw of the file includes, separated by a comma (according to the CSV standard), the filename of the sample (e.g. 000000.jpg) and the estimated attributes (e.g. 3,2,1,1,1). Therefore, an example of raw may be 000000.jpg,3,2,1,1,1. The file of the results will be formatted exactly in the same way. The provided sample test.py includes the writing of the results file.
The submission must be done by email. The archive file can be attached to the e-mail or shared with external links. We strongly recommend to follow the example of code to prepare the submission.
The participants are strongly encouraged to submit a contest paper to CAIP 2023, whose deadline is 10th July, 2023. The contest paper must be also sent by email to the organizers. If you submit a paper, you can cite the paper describing the contest by downloading the bibtex file or as follows:
- Greco A., Vento B., "PAR Contest 2023: Pedestrian Attributes Recognition with Multi-Task Learning", 20th International Conference Computer Analysis of Images and Patterns, CAIP 2023. Online available here
Results
Before the deadline, 11 teams sent an official request for participating to the contest: 7 from Europe, 4 from Asia.
Finally, 5 teams submitted a valid method to the contest, reported in alphabetic order:
AWESOMEPAR, CODY, HUSTNB, IROC-ULPGC, SPARKY.
In the following table, the final ranking of the contest is reported:
| $Rank$ | $Team$ | $A_u$ | $A_l$ | $A_g$ | $A_b$ | $A_h$ | $mA$ |
|---|---|---|---|---|---|---|---|
| 1 | IROC-ULPGC | 0.9207 | 0.9081 | 0.9272 | 0.9215 | 0.9279 | 0.9211 |
| 2 | HUSTNB | 0.7284 | 0.7478 | 0.8448 | 0.6308 | 0.8678 | 0.7639 |
| 3 | SPARKY | 0.7387 | 0.9041 | 0.8833 | 0.6635 | 0.5772 | 0.7533 |
| 4 | CODY | 0.5970 | 0.7431 | 0.8478 | 0.4463 | 0.5438 | 0.6356 |
| 5 | AWESOMEPAR | 0.1817 | 0.1377 | 0.9358 | 0.7712 | 0.7559 | 0.5565 |
Organizers

Antonio Greco
Tenure-Track Assistant ProfessorDept. of Information and Electrical Engineering and Applied Mathematics (DIEM)
University of Salerno, Italy

Bruno Vento
PhD StudentDept. of Electrical Engineering and Information Technology (DIETI)
University of Napoli, Italy
Contact
par2023@unisa.it
+39 089 963006